728x90
반응형
논문 : Cui, Henggang, et al. "Deep kinematic models for kinematically feasible vehicle trajectory predictions." 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
요약
- 본 논문은 딥러닝 기반의 주행 객체 궤적을 예측하는 방법을 제시한다.
- 주행 객체 궤적 예측 시, 차량의 Kinematics를 encode하는 방법을 제안한다.
- 제안 방법은 어떤 딥 러닝 아키텍처에도 적용할 수 있는 General한 방법이다.
관련 연구
- 클래식 Motion 예측 방법
- 주행 객체의 Kinematics를 바탕으로 인지 시점의 객체의 Control input이 유지될 것이라 가정함
- 예측 horizon이 길어질수록 부정확해진다는 단점 존재
- 정밀 지도 정보를 바탕으로, 주행 객체가 인지 시점에서 주행 가능한 모든 Motion을 고려함
- 주행 객체의 특이 Motion 발생 가능성에 대해서 고려하지 못함
- 주행 객체의 Kinematics를 바탕으로 인지 시점의 객체의 Control input이 유지될 것이라 가정함
- 학습 기반 Motion 예측 방법
- RNN(Recurrent Neural Network)과 Long Short - Term Memory (LSTM), Gated Recurrent Unit (GRU)와 같은 방식이 미래 객체 예측에 적용됨.
- 많은 Motion 예측 방식들이, 객체의 위치만 예측하고 kinematic constraints (ex/ 차량 최소 회전 반경)을 고려하지 못함.
- 보통 뉴럴 네트워크의 출력을 decoding 하는 layer를 하나 더 둠으로서 Kinematic constraints를 고려함
- 본 논문에서는 모델의 아키텍처나 학습 기법에 일반적인 Kinematic layer를 제안함
제안 방법
- 본 논문에서는 차량의 Bounding Box, 위치, 속도, 가속도, 헤딩, 각속도를 추정한다. 그리고 각 상태는 0.1s 간격의 discrete 형태로 표현한다.
- 각 상태 값들은 객체 기준의 로컬 좌표계로 표현된다. 차량의 종방향이 x-axis, 왼쪽 방향이 y-axis이다. 각 객체의 Box 중심이 원점으로 표현된다.
Unconstrained motion Prediction
- 기존의 연구들은 뉴럴 네트워크에서 경로 포인트의 x, y 좌표값을 바로 예측함. 그리고 경로 포인트 간 벡터 값으로 부터 차량의 헤딩값과 속도값을 계산함.
- 본 논문에서 i번째 객체의 time t_j에서의 loss는 예측 경로 포인트와 관측된 실제 경로 포인트 간 Euclidean distance로 정의함.
- $$ L_{ij} = \sqrt{(x_{i(j+h)} - \hat{x}_{i(j+h)})^2+(y_{i(j+h)} - \hat{y}_{i(j+h)})^2} $$
- 뉴럴 네트워크에서 추정한 값은 hot notation을 추가함.
- 본 논문에서는 multimodel 예측 방법을 사용함. 즉 뉴럴 네트워크에서 객체의 궤적을 1개가 아닌 m개로 예측하고 각 궤적 별 확률 값을 계산함 (by softmax). 학습 시에는 실제 경로 포인트와 가장 가까운 궤적(m*) 값을 찾고, 이에 대해서만 Loss 값을 구함. 즉 최종 Loss 값은 아래와 같음.
- $$ L_{ij} = \sum_{m=1}^{M}I_{m=m^*}(L_{ijm}-\alpha \,log\, p_{ijm}) $$
- I_c 값은 binary indicator 함수이다. c 조건이 참이면 1, 거짓이면 0이다.
- L_ijm은 관측 궤적과 가장 가까운 예측 궤적 m*에 대해 Euclidean Distance loss 값을 계산한 것이다.
- alpha 값은 hyper parameter이다.
- p_ijm은 관측 궤적과 가장 가까운 예측 궤적 m*의 output 확률 값이다.
- 상기 최종 Loss 식에 의해, 학습 시 실제 관측 값과 가장 가까운 경로 포인트 예측 값에 대해서만 이루어진다. 반면 확률 값은 soft-max에 의해 모든 예측 값에 대해 학습된다. (이 부분이 이해되지 않음, binary indicator에 의해 가장 가까운 궤적의 확률에 대해서만 학습되는거 아닌가?)
- 상기 과정을 모든 주행 객체에 대해 수행한다고 하면, 뉴럴 네트워크의 최적 모델 파라미터는 아래와 같이 표현할 수 있다.
- $$ \mathbf{\theta}^* = \underset{\theta}{arg\, min}L = \underset{\theta}{arg\, min}\sum_{j=1}^{T}\sum_{i=1}^{N_j}L_{ij} $$
- theta_star : 뉴럴 네트워크 파라미터
- 상기 과정의 입력 이미지 (raster image)와 출력 결과는 아래 그림과 같다.
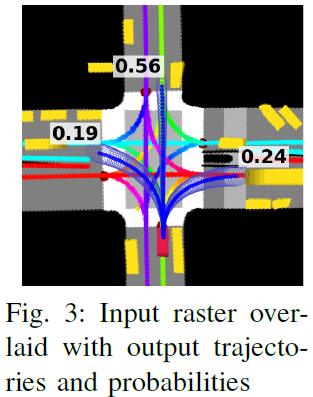
Deep kinematic model (DKM)
- DKM은 상기 뉴럴 네트워크의 출력으로부터 객체의 주행 궤적을 계산하기 위해 추가된 Layer이다.
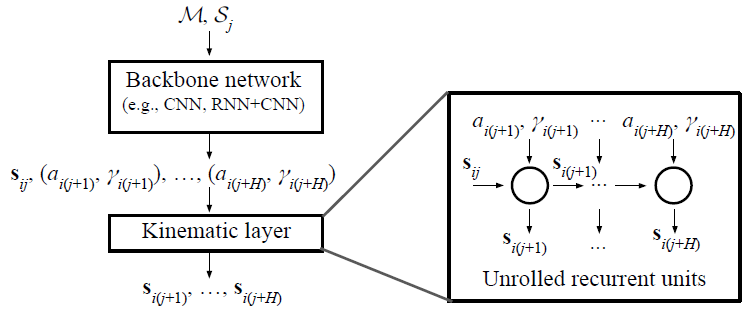
- 백본 뉴럴네트워크에서는 time step 별 주행 객체의 종방향 가속도와 조향각을 예측한다. 이 값을 이용해 Kinematic layer에서는 time step 별 차량의 위치, 헤딩, 속도 등을 계산한다.
- Kinematic Layer은 time step의 개수 H만큼, 노드 H개로 구성된다. (H : predict horizon) 이전 노드의 state와 해당 노드의 종방향 가속도 및 조향각 입력을 이용해 현재 state 값을 계산(전개, roll out) 한다. 이때 사용되는 식은 자주 사용하는 Kinematic Vehicle Model이다.

- Kinematic Layer의 가장 첫번째 노드의 입력 state는 주행 객체의 현재 State이다. 다음 time step 별 state는 sequential하게 계산된다. 이 궤적이 Kinematically feasible 함을 보장하기 위해, 각 control는 허용된 range로 제한된다. (만약 제한 값을 초과하면, 제한 값을 입력으로 넣겠지?)
- Kinematic Layer에서 가장 중요한 것 중 하나는 Kinematic 계산식들이 모두 미분가능하다는 것이다. 이로 인해 뉴럴 네트워크의 출력 값이 종방향 가속도와 조향각이고, 실제 학습에 사용되는 값은 경로 포인트 위치 값으로 서로 다른데도 end-to-end 학습이 가능하게 된다. 즉, 미분 가능하다는 특성으로 인해 본 Kinematic Layer은 학습 기법과 모델 아키텍처에 관계없이 적용 가능한 것이다.
실험
- 본 연구에서는 수동으로 주행한 240시간 가량의 데이터를 지도 학습 형태로 학습시켰다.
- 본 결과를 SOTA detector와 Unscented Kalman Filter tracker의 결과와 비교하였다.
- 주행 객체의 horizon은 6초로 설정하였다.
- 학습/검증/테스트 데이터는 3 : 1 : 1로 나누었다.
728x90
반응형


