Paper : Gao, Jiyang, et al. "Vectornet: Encoding hd maps and agent dynamics from vectorized representation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Website : https://blog.waymo.com/2020/05/vectornet.html

요약
- 자율주행 차량의 Motion Planning을 위한 주변 Agent의 Behavior prediction에 사용 가능한 뉴럴 네트워크 아키텍처 제안
- 도로 상황을 Rasterized Image (2D or 3D)가 아닌 Vector 형태로 표현해 뉴럴 넷의 입력으로 사용한 것이 특징
- 이러한 방법을 제안하는 첫 논문이라고 함
- 기존에는 도로 상황을 bird eye's view 관점에서의 이미지로 표현한 후 CNN을 사용해 학습하는 방식이 주였음.
- 본 연구는 Waymo에서 수행하였고, ArgoverseDataSet에서 1위를 찍었다고 함
Vector Net
1) How to vectorize trajectories and maps
- 정밀 지도(HD map)의 구성 요소들은 spline (차선), closed shape (교차로), point (교통 신호기)와 같은 기하학적 요소로 표현할 수 있다. 그리고 교통 신호의 색, 도로의 속도 제한 등의 attribute 값을 가지고 있다.
- 주행 객체의 궤적은 시간에 따라 특정 방향을 가진 spline으로 표현할 수 있다.
- 따라서 정밀 지도 구성 요소들과 객체의 궤적들은 모두 vector의 sequence로 표현할 수 있다. 정밀 지도 요소들은 시작점과 방향을 결정한 후, 동일한 길이 별로 key point를 샘플링한다. 전후 point를 연결하면 vector로 만들 수 있다. 궤적의 경우도, 특정 타임 스텝 (0.1s)에 따라 key point를 샘플링한 후 연결하면 vector가 된다. (샘플 단위 길이, 시간이 작을 수록 정확하게 근사 가능하다.)
- 정밀 지도의 구성 요소들과 객체들의 궤적을 하나씩 vectorize 한다. 동일한 polyline에 속한 Vector들은 하나의 그래프로 표현된다. 이때 각 vector는 Graph node feature이다. 하나의 polyline은 fully connected, un-ordered graph 로 표현한다.
- $$ \textbf{v}_i = \left [ \textbf{d}_{i}^{s}, \textbf{d}_{i}^{e}, \textbf{a}_i, j \right ] $$
- d_i^s : 시작점 (x,y - 2D / x,y,z - 3D)
- d_i^e : 종료점
- a : attribute feature (객체 타입, 궤적의 타임스탬프, 차로의 곡률 제한 등)
- j : Polyline의 integer ID
- 정밀 지도 벡터의 좌표계 : Ego Vehicle의 로컬 좌표계, 객체 궤적의 좌표계 : 각 객체의 로컬 좌표계
2) Polyline subgraph construct
- 하나의 polyline = 하나의 Graph로 구성한다. polyline의 Vector는 그래프의 노드이다. 각 Vecotr Node는 동일한 polyline에 속한 다른 모든 Vector Node와 연결된다.
- $$\textbf{P} = \left [ \textbf{v}_{1}, \textbf{v}_{2}, ..., \textbf{v}_p \right ]$$
- Single layer subgraph는 아래 순서로 Propagation한다..
- $$\textbf{v}_i^{l+1} = \varphi _{rel}\left ( g_{enc}\left ( \textbf{v}_i^l \right ), \varphi_{agg}\left ( \left ( g_{enc} \left ( \textbf{v}_j^l \right ) \right ) \right ) \right )$$
- v_i^l : node feature for l-th layer of the subgraph network (즉, 동일한 구성의 그래프가 여러 layer 있는 것)
- v_i^0 : v_i의 input feature
- g_enc : 입력 값을 인코딩해주는 함수 - single fully connected layer + layer normalization + ReLU
- agg : 모든 주변 이웃 노드로부터 얻은 정보를 aggregate 해주는 역할 - Maxpooling
- rel : 노드 v_i와 주변 이웃 노드 간 releational operator - Simple concatenation
- 상기 식은 다음 그림 처럼 표현된다.
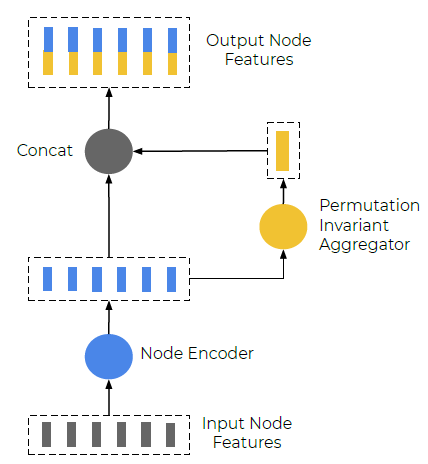
- Subgraph는 layer 수만큼 stack 된다. subgraph에서 다음 layer의 subgraph로 propagate되는 과정은 아래와 같다. 각 layer에서 subgraph의 Encoding MLP 가중치는 다르다.
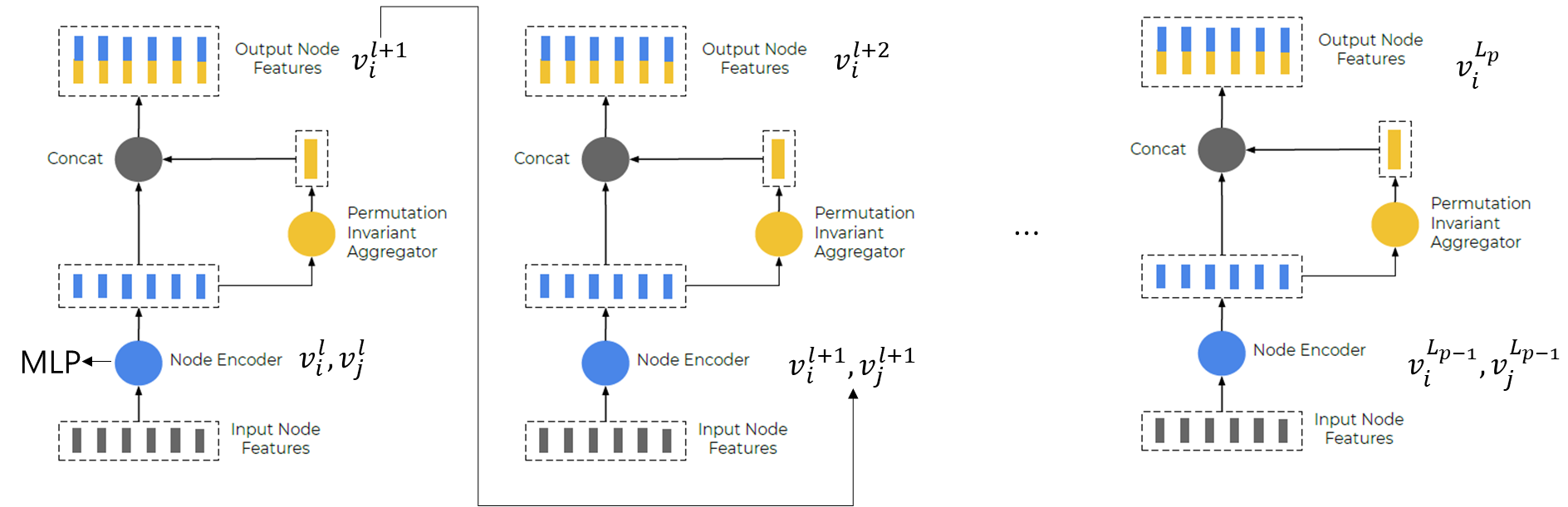
- 최종적으로 polyline level에서 계산되는 feature는 다음과 같다.
- $$\textbf{p}= \varphi_{agg}\left ( \left ( \textbf{v}_j^{L_p} \right ) \right )$$
- agg : maxpooling
- L_p : Num of subgraph Layer
- 즉, 하나의 Polyline은 하나의 요소 (정밀지도 or 궤적)을 표현하고, 이를 여러개의 subgraph layer로 구성한다. 그리고 각 노드 중 가장 큰 값 (Maxpooling)을 Polyline의 대표 값으로 사용하게 된다.
- VectorNet에서 각 vector node의 시작점과 종료점이 같고, annotation인 a가 없다면 PointNet과 동일해진다.

3) High order interations를 위한 Global graph
- 2번째 과정에서 정의한 Polyline 별 Subgraph 간 상호 작용을 위한 Global graph를 모델링한다.
- $$\textbf{p}_i^{(l+1)} = GNN\left ( \textbf{p}_i^{(l)}, A \right )$$
- p_i^l : Polyline node feature들의 집합
- GNN() : Graph neural network의 single Layer
- A : adjacency matrix (본 논문에서는 fully connected graph로 설정)
- Global Graph Network는 self - attention operationi으로 implemented 된다.[2]
- $$GNN(\textbf{P}) = softmax(\textbf{P}_Q \textbf{P}_K^T)\textbf{P}_V$$
- P : node feature matrix
- P_Q, P_K, P_V : linear projections of P
- 본 논문의 목적은 Agent의 미래 궤적을 예측하는 것이다. 그래서 GNN Implemented 이후, Agent의 trajectory node에서 미래 궤적을 decode 한다.
- $$\mathbf{v}_i^{future} = \varphi _{traj}(\textbf{p}_i^{(L_t)})$$
- L_t : GNN 층의 총 갯수
- varphi : trajectory decoder, 본 논문에서는 MLP (다른 논문에서는 anchor-based approach, variational RNN 등이 있음)
- 본 논문에서는 단일 GNN Layer를 사용했다. 따라서 Inference time에서는 target agent의 node feature만 계산해주면 된다.
- Global Graphe의 node간 interaction을 위해 auxiliary graph completion task를 도입함. training 시, polyline subgraph에서 일부 node를 랜덤하게 mask out한다. 그리고 해당 node feature를 아래와 같이 채운다. (이후 일부 과정이 더 있는데 이해를 못했다..이는 [3] 방식을 차용했다고 한다.)
- $$\hat{\textbf{p}}_i = \varphi _{node}\left (\textbf{p}_i^{(L_i)} \right )$$
- varphi : MLP, node feature decoder
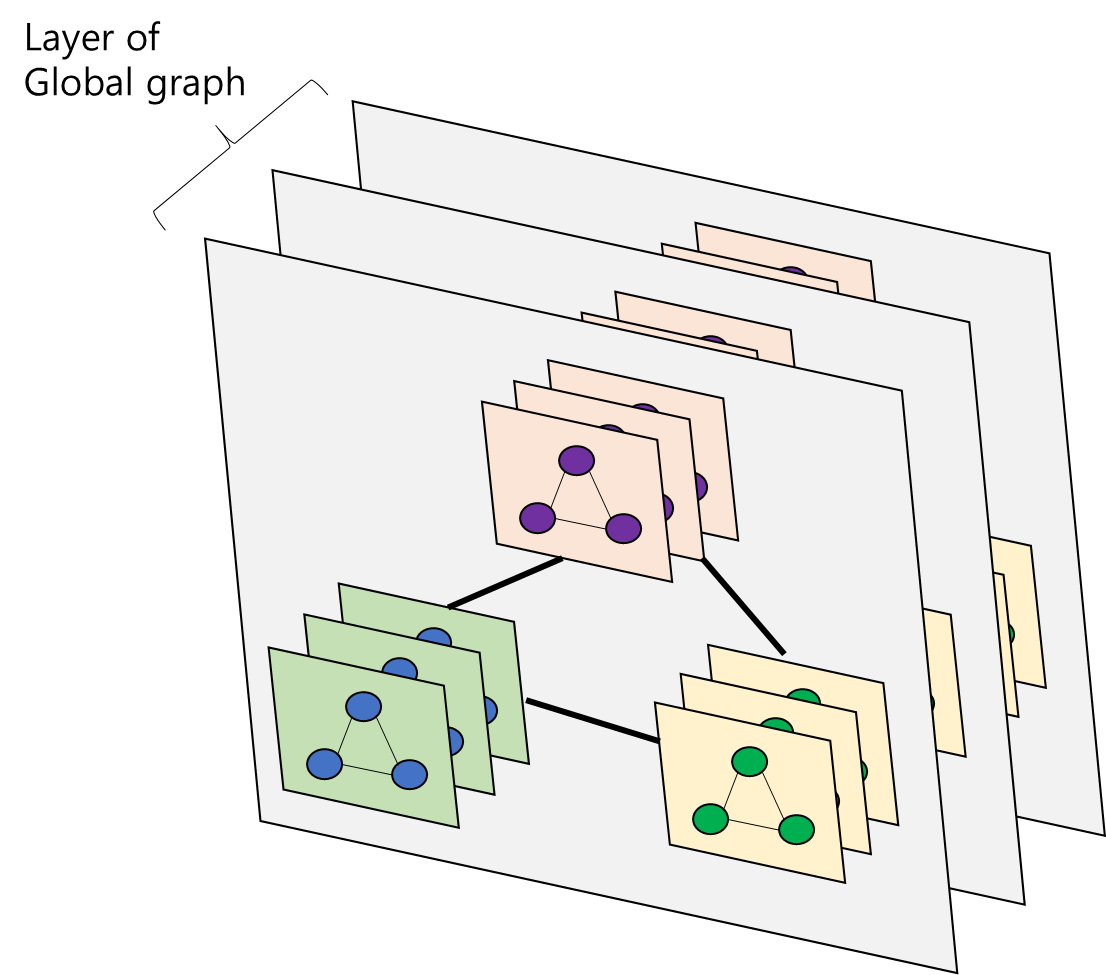
4) Overall framework
- Loss function은 아래와 같다.
- $$L = L_{traj} + \alpha L_{node}$$
- L_traj : negative Gaussian log-likelihood for the groundtruth future trajectories.
- L_node : Huber loss between predicted node features and groundtruth masked node features.
- node feature의 크기를 낮추는 것을 방지하기 위해, Global graph network로 feeding 하기 전에 L2 Normalize를 한다.
References
[1] Graph Neural Networks (GNN) - https://iridescentboy.tistory.com/m/79
[2] Attention is all you need, NIPS, 2017.
[3] BERT : Pretraining of deep bidirectional transformers for language understanding.
공부 필요한 요소
GNN, Attention is all you need 논문, Transformer
'개념공부 > AI, 머신러닝 등' 카테고리의 다른 글
| [논문 리뷰] Deep Kinematic Models for Kinematically Feasible Vehicle Trajectory Predictions (0) | 2022.11.14 |
|---|---|
| Graph Neural Networks (GNN) (0) | 2022.11.11 |
| [논문 리뷰] Safetynet: Safe planning for real-world self-driving vehicles using machine-learned policies (0) | 2022.11.03 |
| [CS231n] Lecture3. Loss Functions and Optimization 정리 (0) | 2020.10.06 |
| [CS231n ] Lecture 2. Image Classification 정리 (0) | 2020.10.06 |


