패스트 캠퍼스 강화학습 교육에서 들은 Dynamic Programming 기법을 경로 생성 로직에 적용할 수 있는 방안을 고민해보았다. 요즘 최 우선 기능 개발 목표가 수치 최적화 기반의 교차로 우회전 경로 생성이다. 수치 최적화 그리고 교차로 우회전 경로 생성이 중요한 것이 아니다. 대신 로직이 충돌판단, 차량의 Kinematic Constraint 고려, 부드러운 경로 생성을 모두 반영한 Full stack 경로 생성 로직을 하나의 알고리즘에 녹여낼 수 있는 것이 수치 최적화 기반이고, 위 3가지 특징을 모두 요구하는 구간이 교차로 우회전이기 때문에 개발 진행 중이다.
DP는 MDP로 정의된 문제에서, state transition probability와 reward를 알고 있을 때 사용할 수 있는 기법이다. (환경을 안다고 표현한다.) 따라서 경로 생성 문제에 DP를 사용하기 위해선 1. 문제가 MDP로 정의되어야 하고, 2. state transition probability와 reward를 알아야 한다.
경로 생성 문제는 MDP로 정의될 수 있다. 특정 영역을 하나의 state로 정의하는 것이다. 그럼 state가 이동함에 따라 (probability가 1이고, Action을 선택함에 따라) 위험도 판단, 곡률 변화량을 고려해 reward를 얻을 수 있다.
실제 경로 생성 환경에서는 state 간 probability와 reward가 환경적으로 정해져 있지 않다. 대신 내가 직접 설정해주어야 한다. 그렇다면 경로 생성 로직의 요구 사양 중 충돌 판단, 곡률 체크 부분을 reward로 표현해 내야 한다. 이 부분이 어려운 점이다.
문제 구성은 아래와 같다.
주행가능영역의 좌우 바운더리, 시작점, 종료점이 입력되었다고 가정한다. 나는 시작점과 종료점을 연결하되, 주행 가능 영역 바운더리와 충돌하지 않고 차량의 곡률 회전 반경보다 곡률이 큰 경로를 생성해야 한다.
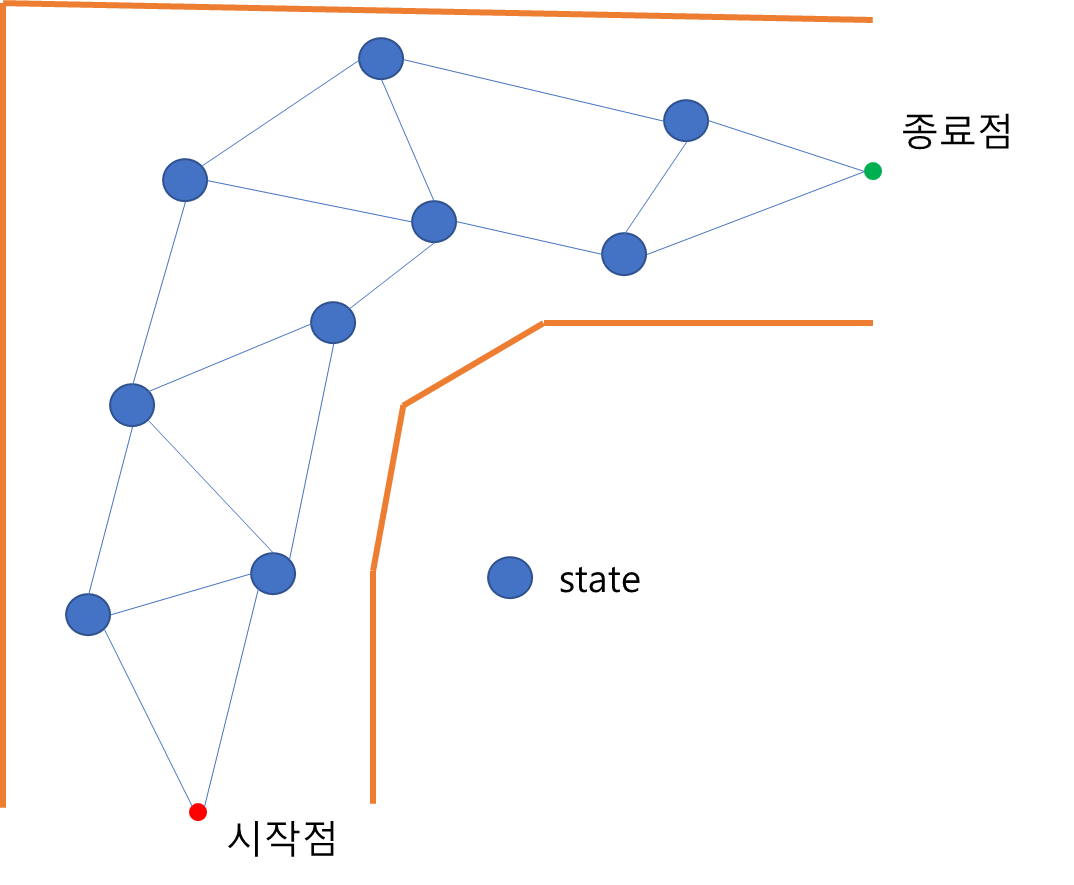
음,, 다시 생각해보니 가능할까 모르겠다..
파트 내 다른 연구원님은 위 문제는 그래프에서 시작점과 종료점 간 특정 cost를 min 화 하는 문제이므로, 굳이 DP를 쓰지 않고 기존의 Dikjstra 와 같은 알고리즘을 사용하면 쉽게 풀릴 수 있다고 한다.
좀더 고민해보자..
'개념공부 > 강화학습(Reinforcement Learning)' 카테고리의 다른 글
| 강화학습 5 <Policy-based RL의 시작 : REINFORCE> (1) | 2021.12.26 |
|---|---|
| 강화학습 4 <인공신경망을 활용한 강화학습 - Deep SARSA> (0) | 2021.12.24 |
| 강화학습 3 <환경을 모를때 MDP 풀이, MC, TD, SARSA, Q-Learning> (0) | 2021.12.01 |
| 강화학습 - 2 <MDP를 푸는 Dynamic Programming 기법> (0) | 2021.11.28 |
| 강화학습 - 1 <Markov 개념> (0) | 2021.11.27 |

