
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- MDP
- DynamicProgramming
- Recursion
- 선형대수
- Dubins Path
- Hybrid A star
- 동적라이브러리
- CPP
- Motion Planning
- 백준
- C
- solver
- Leetcode
- Graph Neural Network
- GNN
- 정적라이브러리
- path planning
- self driving car
- GIT
- 수치최적화
- OSQP
- 경로생성
- PathPlanning
- 소프티어
- Frenet Coordinate
- 공유라이브러리
- autonomous vehicle
- CUDA
- C++
- 강화학습
- Today
- Total
Swimmer
CUDA 2. Programming Model 본문
원글 : https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
2.1. Kernel (CUDA에서의 함수, N개의 thread에서 독립적으로 한번씩 실행되는 함수)
Kernel이란 1회 호출 시, 복수개의 CUDA 쓰레드에서 동시에 실행되는 C++ 형식의 함수를 의미한다. Kernel은 CUDA C++에 포함되어 있다. 일반 C++ 함수는 1회 호철 시 1번 실행되는 것과 달리 Kernel은 1회 호출하더라도 복수번 실행되는 것이 특징이다.
Kernel은 '__global__' 이라는 선언자를 통해 정의된다. Kernel 호출 시 실행되는 복수개의 Thread는 각각 ID가 부여된다. 실행될 Thread의 개수는 <<<...>>> syntax (문법)을 사용해 정의한다. 아래는 NVIDIA CUDA Toolkit의 예시 코드이다.
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}__global__ 선언자를 통해 VecAdd 라는 Kernel을 정의했다. VecAdd 함수는 크기가 N인 A, B 2개의 벡터를 합한 결과를 벡터 C에 저장하는 기능을 수행한다. VecAdd Kernel 실행시 N개의 thread가 각 한번의 계산을 실행한다.
2.2. Thread Hierarchy ( Thread, Block, Grid 개념 이해 및 Kernel 호출 시 사용 방법 익히기)
CUDA는 GPU의 복수개의 core를 동시에 쓰는 것이 핵심이기 때문에, 하나의 연산에 복수개의 Thread가 실행된다. 각 Thread에 접근/관리하기 위해 Thread의 인덱스, Thread의 ID가 부여된다. CUDA에서 Thread Idx는 3개의 벡터로 표현되고, 따라서 vector, matrix, volume (Tensor?)를 표현할 수 있다.
만약 계산 대상이 1차원 벡터라면 Thread의 Idx와 Thread의 ID는 동일하다. 2차원 matrix라면 (x, y) 인덱스를 계산하는 Thread는 x + (y * Dx) (Dx : 행 사이즈, Dy : 열 사이즈) 의 ID 값을 가진다. 3차원 volume이라면 (x, y, z) 인덱스를 계산하는 Thread는 x + (y * Dx) + (z * Dx * Dy)의 ID를 가진다.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}현재의 GPU에서는 각 행렬 계산마다 사용할 수 있는 Thread는 1024개이다. 실행되는 Thread의 총 개수는 아래와 같이 계산된다. Thread의 총 개수 = 한 Block 당 thread 개수 X Block의 개수. 여기서 Block은 계산되는 한 식, Thread는 실행돼야할 식의 개수로 보인다. 위 예제를 보면 Block은 1로, ThreadsPerBlock은 N*N으로 계산했다. 각 syntax의 자료형이 int 혹은 dim3임에 주의하자. 위 예제에서 Block는 1개인데, 이를 복수개로 설정할 경우 위 코드는 아래와 같이 된다.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}위 예시들을 보다보면, Thread, Block, Grid의 개념들이 헷갈리는데 NVIDIA에서는 이를 아래 그림과 같이 설명한다.
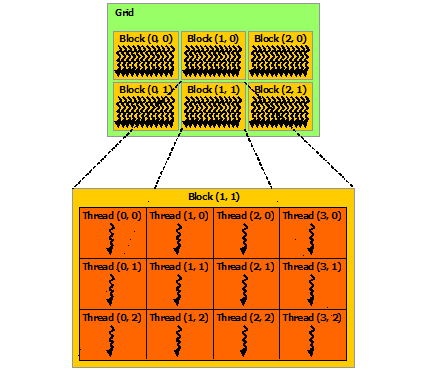
Thread - Block - Grid 순서로 포함되는 관계이다. 각 Thread는 1개의 연산을 수행한다.
2.3. Memory Hierarchy
각 Thread는 private local memory를 가진다. 모든 Thread들은 동일한 global memory에 접근 가능하다. 그리고 Block는 Thread들이 접근할 수 있는 shared memory를 가진다.
그리고 모든 Thread들은 Read-Only로 접근 가능한 2개의 memory 영역이 있는데 이는 constant 및 texture memory 영역이다. (Texture memory는 video 데이터에 있는 memory 인듯. Rendering 에 사용되는 데이터?)
2.4. Heterogeneous Programming
CUDA Programming은 CUDA thread가 GPU에서 돌고, 일반 thread는 CPU에서 돌기 때문에 Heterogeneous Programming이다. 일반 코드를 Serial 하게 CPU에서 읽어내려가다가 CUDA Kernel 호출 시 GPU에서 CUDA Thread가 돌게 된다. CUDA Thread가 모두 돌고 나면 다시 CPU에서 일반 코드를 Serial 하게 읽어 나간다.
Cuda 프로그래밍 모델에서는 CPU (Host)와 GPU (Device)가 각자의 분리된 memory를 DRAM에서 가지고 있다고 가정한다. 따라서 CUDA Thread가 돌기 위해서는 CPU(Host) 와 GPU(Device) 간에 데이터 전달을 위한 Device 메모리 할당 및 해제가 필요하다.
아래는 Serial code와 Parallel Kernel이 각각 CPU(Host)와 GPU(Device)에서 도는 것을 보여준다.
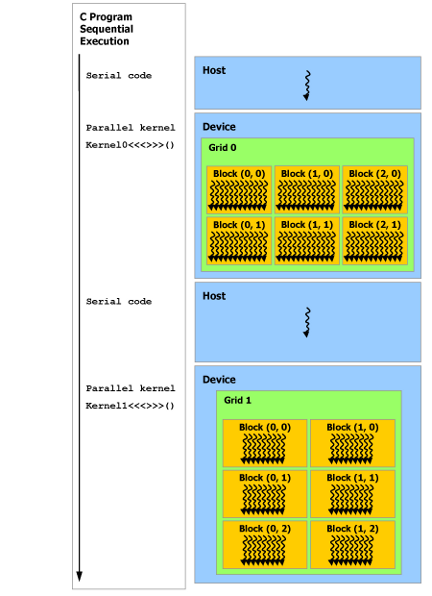
2.5. Asynchronous SIMT Programming Model (비동기 SIMT 프로그래밍 모델)
CUDA Programming Model은 asynchronous programming model을 통해서 메모리 operation 가속화를 제공한다. asynchronous programming model이란 CUDA thread에서 할 수 있는 asynchronous operation을 의미한다.
asynchronous model은 여러개의 CUDA threa간의 synchronization을 위한 asynchronous barrier의 행동을 정의한다. 그리고 이 모델은 GPU에서 computing 하는 동안 global memory에 저장된 데이터를 asynchronously하게 처리할지에 대한 cuda::memcpy_async를 정의하고 설명한다.
* GPU에서 데이터를 처리 (가져오고, 내보내고)하는데 asynchoronous operation을 사용하는 것 같은데, 자세히는 잘 모르겠다. 나중에 예제 코드 보고 이해 하자.
2.6. Compute Capability
GPU 하드웨어가 제공 가능한 기능을 명시하기 위한 숫자로 Major Revision X, Minor Revision Y를 사용해 X.Y로 표기된다. PC에 설치된 GPU로 어떤 기능을 쓸 수 있는지 확인하기 위해선 Compute Capability 값을 보고 이 값에 해당하는 기능들을 보면 된다.
'개념공부 > CUDA' 카테고리의 다른 글
| CUDA 예제 프로그램 작성 및 실행 (0) | 2022.04.28 |
|---|---|
| CUDA Tool kit 설치 (0) | 2022.04.28 |